Using the ring_buffer for viewing Azure SQL Database extended events is pretty challenging.
Below is my attempt to automate the process.
Simply add the extended event session name you are wanting to view.
Make sure the extended event session is using the ring_buffer output, and is running, and then run the generated sql_command shown.
If you have any comments on improvements i.e. showing deadlock xml, feel free to comment.
/* extended event session name */
DECLARE @session_name nvarchar(128);
/*only update this line with the name of the session to view*/
SET @session_name = 'your extended event session name';
/* temporary table variable */
DECLARE @sqlcmd_table TABLE (row_order int IDENTITY(1,1), row_text varchar(MAX));
/* select start */
INSERT INTO @sqlcmd_table (row_text) SELECT 'DECLARE @t1 TABLE (target_data xml);';
INSERT INTO @sqlcmd_table (row_text) SELECT 'INSERT INTO @t1 (target_data)';
INSERT INTO @sqlcmd_table (row_text) SELECT 'SELECT CAST(target_data AS xml) AS target_data';
INSERT INTO @sqlcmd_table (row_text) SELECT 'FROM sys.dm_xe_database_sessions a, sys.dm_xe_database_session_targets b';
INSERT INTO @sqlcmd_table (row_text) SELECT 'WHERE 1=1';
INSERT INTO @sqlcmd_table (row_text) SELECT 'AND a.[address] = b.event_session_address';
INSERT INTO @sqlcmd_table (row_text) SELECT 'AND b.target_name = ''ring_buffer''';
INSERT INTO @sqlcmd_table (row_text) SELECT 'AND a.[name]= '''+@session_name+''';';
INSERT INTO @sqlcmd_table (row_text) SELECT '';
INSERT INTO @sqlcmd_table (row_text) SELECT 'SELECT'
INSERT INTO @sqlcmd_table (row_text) SELECT ' c.value(''(@timestamp)[1]'',''datetime2'') AT TIME ZONE ''UTC'' AT TIME ZONE ''New Zealand Standard Time'' AS timestamp_nz';
INSERT INTO @sqlcmd_table (row_text) SELECT ',c.value(''(@name)[1]'',''nvarchar(128)'') AS event_name';
INSERT INTO @sqlcmd_table (row_text) SELECT ',c.value(''(@package)[1]'',''nvarchar(128)'') AS package_name';
/* action columns */
INSERT INTO @sqlcmd_table (row_text)
SELECT
',c.value(''(action[@name='''''+c.action_name+''''']/value)[1]'','''+ CASE WHEN d.[type_name] = 'activity_id' THEN ''
WHEN d.[type_name] = 'activity_id_xfer' THEN ''
WHEN d.[type_name] = 'ansi_string' THEN 'varchar(MAX)'
WHEN d.[type_name] = 'ansi_string_ptr' THEN 'varchar(MAX)'
WHEN d.[type_name] = 'binary_data' THEN 'varbinary(MAX)'
WHEN d.[type_name] = 'boolean' THEN 'bit'
WHEN d.[type_name] = 'callstack' THEN 'nvarchar(MAX)'
WHEN d.[type_name] = 'char' THEN 'char(1)'
WHEN d.[type_name] = 'cpu_cycle' THEN 'bigint'
WHEN d.[type_name] = 'filetime' THEN 'datetime'
WHEN d.[type_name] = 'float32' THEN 'float(24)'
WHEN d.[type_name] = 'float64' THEN 'float(53)'
WHEN d.[type_name] = 'guid' THEN 'nvarchar(MAX)'
WHEN d.[type_name] = 'guid_ptr' THEN 'bigint'
WHEN d.[type_name] = 'int16' THEN 'smallint'
WHEN d.[type_name] = 'int32' THEN 'int'
WHEN d.[type_name] = 'int64' THEN 'bigint'
WHEN d.[type_name] = 'int8' THEN 'tinyint'
WHEN d.[type_name] = 'null' THEN 'null'
WHEN d.[type_name] = 'ptr' THEN 'bigint'
WHEN d.[type_name] = 'uint16' THEN 'smallint'
WHEN d.[type_name] = 'uint32' THEN 'int'
WHEN d.[type_name] = 'uint64' THEN 'bigint'
WHEN d.[type_name] = 'uint8' THEN 'tinyint'
WHEN d.[type_name] = 'unicode_string' THEN 'nvarchar(MAX)'
WHEN d.[type_name] = 'unicode_string_ptr' THEN 'nvarchar(MAX)'
WHEN d.[type_name] = 'wchar' THEN 'nchar(2)'
WHEN d.[type_name] = 'xml' THEN 'xml'
ELSE 'nvarchar(MAX)' END + ''') AS ' + c.action_name
FROM
sys.dm_xe_database_session_events b
,sys.dm_xe_database_session_event_actions c
,sys.dm_xe_objects d
WHERE 1=1
AND b.event_session_address = c.event_session_address
AND b.event_name = c.event_name
AND b.event_package_guid = d.package_guid
AND c.action_name = d.[name]
AND d.object_type = 'action'
ORDER BY b.event_name, c.action_name
/* event columns */
INSERT INTO @sqlcmd_table (row_text)
SELECT
',c.value(''(data[@name='''''+a.[name]+''''']/value)[1]'',''nvarchar(MAX)'') AS '+a.[name]
FROM
sys.dm_xe_object_columns a JOIN sys.dm_xe_database_session_events b
ON a.object_package_guid = b.event_package_guid
AND a.[object_name] = b.[event_name]
LEFT OUTER JOIN sys.dm_xe_database_session_object_columns c
ON c.object_package_guid = a.object_package_guid
AND c.event_session_address = b.event_session_address
AND c.[object_name] = a.[object_name]
AND c.column_name = a.[name]
WHERE 1=1
AND a.column_type <> 'readonly'
AND (c.column_value IS NULL OR c.column_value = 'true') /* remove not selected */
ORDER BY b.event_name, a.column_id;
/* select end */
INSERT INTO @sqlcmd_table (row_text) SELECT 'FROM @t1 a' + CHAR(13) + CHAR(10) ;
INSERT INTO @sqlcmd_table (row_text) SELECT 'CROSS APPLY target_data.nodes(''RingBufferTarget/event'') AS b(c)'
INSERT INTO @sqlcmd_table (row_text) SELECT 'ORDER BY c.value(''(@timestamp)[1]'',''datetime2'') DESC;';
/* view sql command */
SELECT row_text AS sql_command
FROM @sqlcmd_table
ORDER BY row_order;
/* Make sure the extended event session is running and you run the the generated sql_command in the Azure SQL Database */
The following code will check if a SQL Server Agent job is running and then stop it if it is.
The code can be placed in a SQL Server Agent job and scheduled to run at a suitable time i.e. to ensure a maintenance job is not going to run into business hours.
DECLARE @job_name_to_stop nvarchar(128);
/*only update this line with the name of the job to stop*/
SET @job_name_to_stop = N'long running job name';
IF (SELECT TOP 1 1
FROM msdb.dbo.sysjobs_view a, msdb.dbo.sysjobactivity b, msdb.dbo.syssessions c
WHERE 1=1
AND a.job_id = b.job_id
AND b.session_id = c.session_id
AND c.agent_start_date = (SELECT MAX(d.agent_start_date) FROM msdb.dbo.syssessions d)
AND b.run_requested_date IS NOT NULL AND b.stop_execution_date IS NULL
AND a.name = @job_name_to_stop
) = 1
BEGIN
EXEC msdb.dbo.sp_stop_job @job_name = @job_name_to_stop;
END
You are unable to use DATA_COMPRESSION with ALTER INDEX REORGANIZE e.g.
ALTER INDEX CI_c1 ON test_compression_clustered REORGANIZE PARTITION = ALL WITH (DATA_COMPRESSION = PAGE);
However if an index has DATA_COMPRESSION you can perform a reorganize with out losing the data compression:
/* compress index */
ALTER INDEX CI_c1 ON test_compression_clustered REBUILD PARTITION = ALL WITH (DATA_COMPRESSION = PAGE);
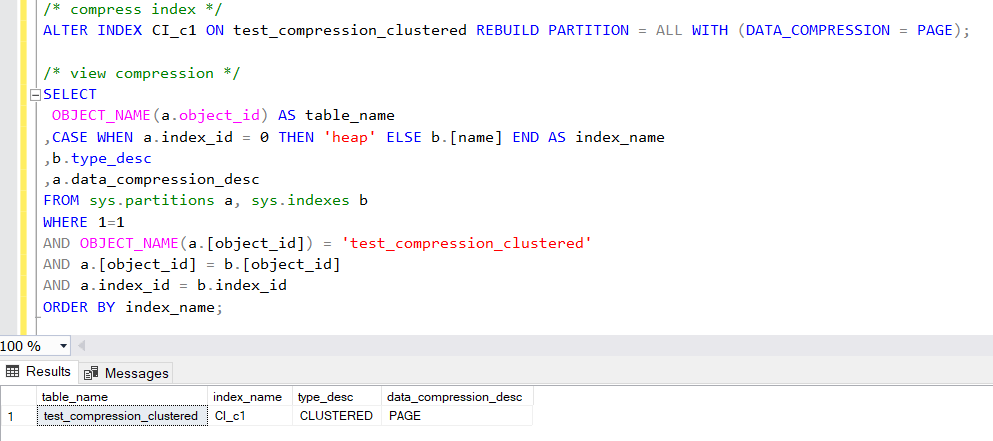
/* view compression */
SELECT
OBJECT_NAME(a.object_id) AS table_name
,CASE WHEN a.index_id = 0 THEN 'heap' ELSE b.[name] END AS index_name
,b.type_desc
,a.data_compression_desc
FROM sys.partitions a, sys.indexes b
WHERE 1=1
AND OBJECT_NAME(a.[object_id]) = 'test_compression_clustered'
AND a.[object_id] = b.[object_id]
AND a.index_id = b.index_id
ORDER BY index_name;
/* REORGANIZE */
ALTER INDEX CI_c1 ON test_compression_clustered REORGANIZE;
/* view compression */
SELECT
OBJECT_NAME(a.object_id) AS table_name
,CASE WHEN a.index_id = 0 THEN 'heap' ELSE b.[name] END AS index_name
,b.type_desc
,a.data_compression_desc
FROM sys.partitions a, sys.indexes b
WHERE 1=1
AND OBJECT_NAME(a.[object_id]) = 'test_compression_clustered'
AND a.[object_id] = b.[object_id]
AND a.index_id = b.index_id
ORDER BY index_name;
When performing an index rebuild operation using SORT_IN_TEMPDB = ON or SORT_IN_TEMPDB = OFF (this is the default), both require additional free space in the data file (mdf) to hold the newly rebuilt index before the old one can be dropped.
When using SORT_IN_TEMPDB = ON, you also require additional space in tempdb, the size of the index being rebuilt!
So if you were under the impression that SORT_IN_TEMPDB = ON doesn’t require the additional space for the rebuilt index in the mdf file, that is not the case.
/* find your time zone name */
SELECT [name] FROM sys.time_zone_info ORDER BY [name];
/* New Zealand Standard Time example 1 */
SELECT
GETUTCDATE() AT TIME ZONE 'UTC' AT TIME ZONE 'New Zealand Standard Time' AS local_time_datetimeoffset
,CAST(GETUTCDATE() AT TIME ZONE 'UTC' AT TIME ZONE 'New Zealand Standard Time' AS datetime) AS local_time_datetime
,CONVERT(char(19),GETUTCDATE() AT TIME ZONE 'UTC' AT TIME ZONE 'New Zealand Standard Time' , 121) AS local_time_char;
/* New Zealand Standard Time example 2 */
SELECT
GETUTCDATE() AT TIME ZONE 'UTC' AT TIME ZONE 'New Zealand Standard Time' AS local_time_datetimeoffset
,CAST(GETUTCDATE() AT TIME ZONE 'UTC' AT TIME ZONE 'New Zealand Standard Time' AS datetime) AS local_time_datetime;
/* New Zealand Standard Time example 3 */
SELECT
session_id
,command
,CAST(start_time AT TIME ZONE 'UTC' AT TIME ZONE 'New Zealand Standard Time' AS datetime) AS local_start_time
,percent_complete AS percent_completed
,CASE
WHEN percent_complete <> 0
THEN CAST(DATEADD(SECOND,estimated_completion_time/1000,GETUTCDATE() AT TIME ZONE 'UTC' AT TIME ZONE 'New Zealand Standard Time') AS datetime) END
AS local_estimated_completion_time
FROM sys.dm_exec_requests
ORDER BY percent_complete;
Starting with SQL Server 2016, this setting is enabled by default for tempdb.
Below is a run down on how it works.
/* use tempdb */
USE [tempdb]
GO
/* file groups shows is_autogrow_all_files as enabled*/
SELECT
name
,is_autogrow_all_files
FROM sys.filegroups;
is_autogrow_all_files enabled
/* current size */
SELECT
name
,physical_name
,type_desc
,(growth* 8)/1024 AS growth_mb
,(size * 8)/1024 AS size_mb
FROM sys.database_files
ORDER BY name;
Ideally all ROWS are the same size
/* change 1 file size */
ALTER DATABASE [tempdb] MODIFY FILE ( NAME = N'tempdev', SIZE = 10MB );
/* current size */
SELECT
name
,physical_name
,type_desc
,(growth* 8)/1024 AS growth_mb
,(size * 8)/1024 AS size_mb
FROM sys.database_files
ORDER BY name;
Modifying 1 file size has no impact on others
/* grow database */
CREATE TABLE #t1 (c1 nchar(4000));
GO
INSERT INTO #t1 (c1) VALUES ('1')
GO 5000
/* current size */
SELECT
name
,physical_name
,type_desc
,(growth* 8)/1024 AS growth_mb
,(size * 8)/1024 AS size_mb
FROM sys.database_files
ORDER BY name;
Auto growth kicked in, but still a mismatch in sizes. Notice that LOG file is not impacted.
Take away from this should be to ensure that your tempdb data files are the same size on startup and use the same growth settings.
You can use sys.master_files to check your tempdb initial size settings.
/* sys.master_files*/
SELECT
name
,physical_name
,type_desc
,(size * 8) /1024 AS size_mb
FROM tempdb.sys.master_files
WHERE DB_NAME(database_id) = 'tempdb'
ORDER BY name DESC;
/* sys.database_files */
SELECT
name
,physical_name
,type_desc
,(size * 8) /1024 AS size_mb
FROM tempdb.sys.database_files
ORDER BY name DESC;